
Tuesday, Oct 03
We’ve had a number of tickets recently asking about running Jupyter Notebooks on Legion/Grace. Until the architecture of the Jupyter Notebook changes this will never be a good/safe idea. This sparked a discussion which descended into an argument between James and myself on the internal Slack about whether it is appropriate to encourage new researchers to use Jupyter notebooks.
Because I like having the last word, I’m going to present James’ arguments first.
James’ first argument is that it’s a great tool for exploring with. I agree, but it’s not the only tool. Python, like many languages, comes with a REPL. Traditionally, that has been the tool for exploring things with. It is no worse than the Notebook, particularly if you install an enhanced one like IPython with tab completion and all sorts of goodies. If you install the QT version of IPython, you can even have all the mixed text/graphics output you get in a notebook. But better than a notebook, the state of the REPL is obvious to the user (more on this later) and the steps the user has taken are documented.
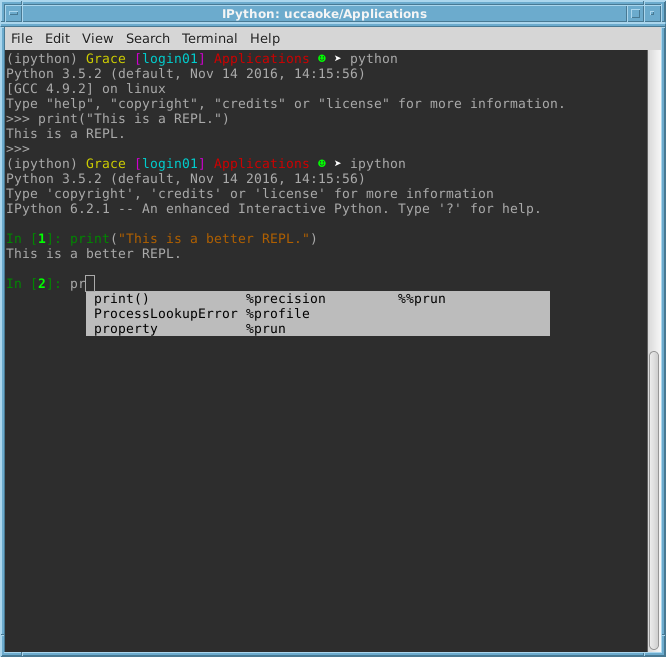
James’ second argument is reasonable: Jupyter notebooks are the easiest tool for practising Literate Programming in Python. And I concede that this is true. It’s quite nice having graphs mixed with your code + documentation.
But this single feature alone doesn’t outweigh the downsides.
Here are the problems with the notebook concept:
1) State
Notebooks have a (hidden) from the user concept of state. That is to say, the order in which you execute code snippets matters.
Supposing we have a notebook that looks something like this:
Block 1:
x = 12
Block 2:
print(x)
Block 3:
x = 13
What is the output from running the second block? Well there are at least three possible options: (12, 13 and an error), depending on which other blocks have been executed beforehand. Now this is a simple example but it gets much worse as soon as packages are involved, and with the widgets and sliders which let users interact with code which has dependencies which may not have been run yet.
I think the moment that the problems were driven home to me was late last year helping my mother set up Julia Jupyter notebooks on her PC for a course (in her retirement she does a lot of MOOCs).
Due to the problems with Julia being not yet mature leading to issues with loading packages/compatibility the whole thing descended into a mess which was extremely hard to debug because you had to make sure to have run the right boxes in the right order.
(In the end my mother resorted to JuliaBox along with most of the people on her course which worked fine for a month until the JuliaBox people updated the version of Julia they run replicating all the problems again).
We spend a lot of time telling researchers that they need to do research in a reproducible, script-able way, and at the same time encourage the use of Notebooks which hide state and which require the user to mimic a series of clicks to run. The two are fundamentally incompatible.
2) File format incompatible with version control
We strongly encourage (again to aid reproducibility) researchers to use a version control system for their code. Jupyter notebooks are stored as JSON files rather than python source which makes diffs largely gibberish, losing one of the primary benefits of version control – being able to track changes.
3) Every user is running a web server all the time
In order for Jupyter Notebooks to function, they run a web server on a high port on the loop-back device (127.0.0.x) on the machine that they are running on. Users connect a web browser to that port (this is lightly disguised on a local machine because the notebook software will launch the web browser for the user).
This brings a couple of big security problems.
a) It is trivial for another user of the same machine to connect to the Notebook server with a web browser and execute code as the person running the server.
This risk is mitigated somewhat by most people running it on their single user laptops but that doesn’t preclude cross-site scripting bugs (same origin protects most of this but it’s notably absent for some modern xhttp request stuff).
(Over on twitter Titus Brown has pointed out that newer versions of the Jupyter Notebook software use token auth to improve things somewhat. Depending on the actions of the user it’s still possible to leak the token to other users of the machine but a lot harder.)
(related there are some really nasty things you can do with certain LISP interpreters when connected to Emacs via SLIME which also uses TCP/IP)
b) It is possible to set up the server so that it runs on an external IP address.
If you do this, anyone who can connect to that IP address can run arbitrary code as the user running the server. You can mitigate this with passwords and TLS but they are up to the user to configure and non-trivial so most don’t bother (certainly with the latter).
It also makes it extremely difficult to run Notebooks within an HPC cluster because they are by default both insecure (it’s a multi-user system) and interactive (which means they aren’t script-able).
4) In order to read your code/document people have to install Jupyter Notebook
This replicates all the issues above for them too (Github can preview Notebooks but at that point you might as well have used any other format). It also makes your work unreadable on mobile devices and brings a whole host of other related problems.
In general, the problems above far outweigh the benefit of being able to put graphics in-line with your comments.
So how could Notebooks be made better?
1) Make them deterministic + reproducible.
Have notebooks run from top to bottom such that a code block depends on the ones above it and running that block runs the precursors in order.
Have a command-line interpreter than can run the notebook like a script in a deterministic way. This would help reproducibility and allow notebooks to be submitted to HPC clusters.
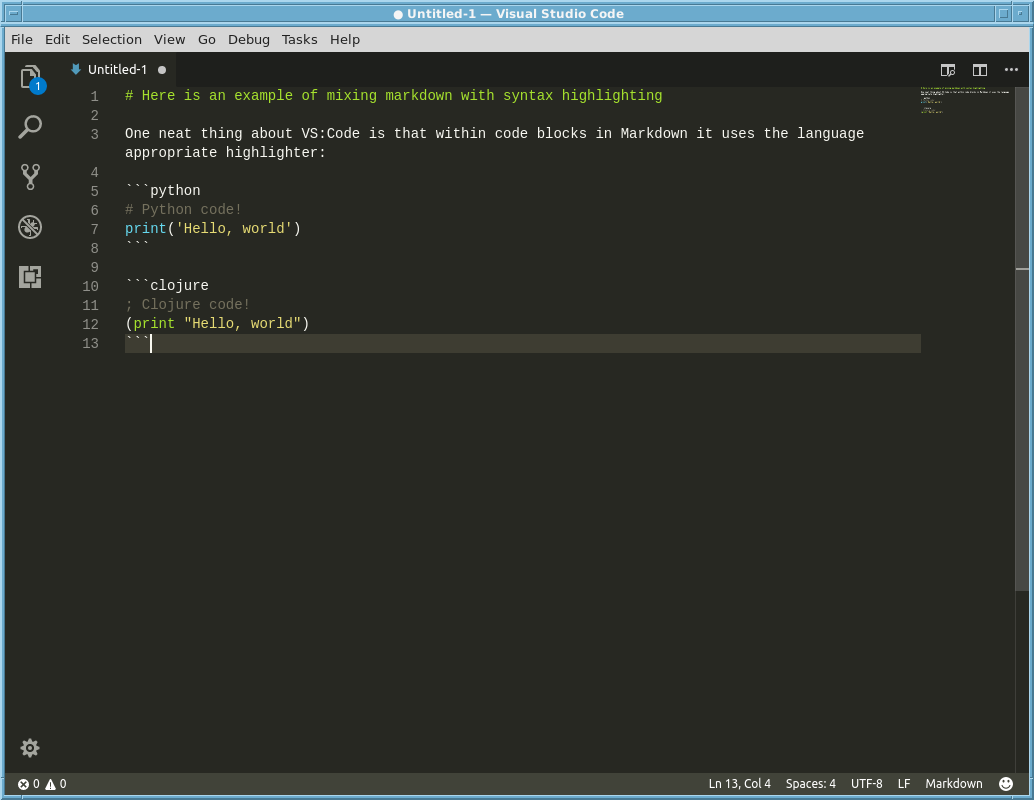
2) Store the notebook as human readable plain text.
I actually think a good start may be something similar to markdown with explicit code blocks. I’ve noticed that if you put code blocks in markdown in Visual Studio Code it syntax highlights the blocks appropriately – see below:
3) Abandon the idea of using HTTP/TCP/IP to access the notebooks.
Much as it’s arguably bloaty and terrible, something like Github Electron would make a good stop-gap until the developers are able to move to another GUI toolkit. Maybe a plugin for Atom?
I think a good standard for a “graphical” terminal + editor mixing text and graphs would be helpful in a lot of areas.
What can I do now?
Until such a tool exists you should:
1) Use a REPL to explore but not to write your code.
2) Write your code in a good editor and version control it.
3) Document your code adequately with comments.
Happy coding!